| |
La
ricerca su World Wide Web
World Wide Web è la risorsa Internet probabilmente più nota, e i suoi
ritmi di espansione sono esponenziali. Le pagine informative immesse in
rete riguardano gli argomenti più vari, e provengono da fornitori di
informazione di natura assai eterogenea: dalle università alle industrie
private (grandi e piccole), dai centri di ricerca ai negozi, dalle imprese
editoriali ai partiti politici. Vi sono poi le numerosissime 'home page'
personali del popolo di Internet.
Chi svolge una ricerca in rete si trova dunque davanti un duplice
problema: reperire l'informazione cercata e valutare la sua
correttezza, completezza, imparzialità.
Il secondo compito, assai delicato, dipende in parte dall'esperienza;
un consiglio generale — una volta trovata una pagina informativa che
reputiamo interessante — è quello di risalire sempre alla home page del
sito che la ospita (su molte pagine sono disponibili apposite icone attive
— altrimenti si può provare ad 'accorciare' progressivamente
l'indirizzo nella barra delle URL, salendo di livello in livello nella
struttura gerarchica del sito). In questo modo potremo in genere reperire
informazioni su chi ha immesso in rete quella particolare pagina, in quale
contesto e a quali fini.
Quanto al primo problema — quello di 'scoprire' le pagine esistenti
che si occupano di un determinato argomento — una buona partenza è in
genere rappresentata dai motori di ricerca disponibili in rete. Vi sono due
tipi di risorse che è bene conoscere: i motori di ricerca per
termini e gli indici sistematici.
I motori di ricerca per termini permettono di ricercare parole o
combinazioni di parole. Se vogliamo ad esempio cercare le pagine che si
occupano di Lewis Carroll (pseudonimo del reverendo Dodgson, l'autore di Alice
nel paese delle meraviglie), potremo fornire al motore di ricerca le
due parole 'Lewis' e 'Carroll'. In molti casi è possibile combinare le
parole fornite utilizzando i cosiddetti operatori booleani: ad esempio,
una ricerca con chiave 'Lewis AND Carroll' potrebbe fornirci le pagine in
cui compaiono tutti e due i nomi, aiutandoci a scremare via pagine che non
ci interessano. Attenzione, però, perché la sintassi corretta per
utilizzare operatori come AND, OR, NOT varia da sito a sito.
La ricerca attraverso un indice per termini è molto comoda nel caso di
nomi propri, o nel caso in cui le informazioni che vogliamo trovare si
lascino caratterizzare attraverso termini molto specifici. Occorre
tuttavia tenere presente che si tratta di una ricerca meccanica: il
programma utilizzato non farà altro che cercare i termini da noi forniti
all'interno di un immenso indice alfabetico in suo possesso — indice
tenuto aggiornato da un 'demone' software che si muove continuamente lungo
la rete, seguendo ogni link incontrato e indicizzando tutte le pagine
percorse — e fornirci le corrispondenze trovate. L'intelligenza della
ricerca dipende dunque in gran parte dalla scelta delle parole usate come
parametri, anche se quasi tutti i motori di ricerca hanno la capacità di
'pesare' i risultati in base a elementi quali il numero di occorrenze
della parola, l'occorrenza in zone significative del documento come i
titoli o i link, e così via. Ciò significa che se abbiamo scelto bene
i nostri termini di ricerca, riceveremo un elenco di pagine che avrà
alte possibilità di iniziare da quelle per noi più significative. Ma se
ad esempio avremo effettuato una ricerca con chiave 'Lewis Carroll', non
troveremo mai le pagine nelle quali compare solo il nome di Dodgson.
Al contrario della ricerca alfabetica, la ricerca sistematica avviene
su cataloghi ragionati di risorse: in genere la base dati è più
ristretta (non saremo sicuri di trovare direttamente tutte, o anche solo
la maggioranza delle pagine che ci interessano), ma la valutazione della
pertinenza o meno di una determinata informazione non sarà più
meccanica, ma risultato di una decisione umana.
Naturalmente, in questi casi i principi utilizzati per costruire
l'impianto sistematico della banca dati sono fondamentali. Un catalogo
ragionato di questo tipo si basa infatti su una sorta di 'albero delle
scienze', da percorrere partendo da categorizzazioni più generali per
arrivare via via a categorizzazioni più specifiche. Ed è importante che
questo percorso di 'discesa al particolare' avvenga attraverso percorsi
intuitivi e coerenti — compito naturalmente tutt'altro che facile.
L'esame dettagliato di alcune fra le risorse disponibili per la ricerca
su World Wide Web ci aiuterà a comprendere meglio questi problemi.
Sottolineiamo però fin d'ora l'importanza di un terzo tipo di
ricerca, del quale è assai più difficile fornire un inquadramento
generale: la navigazione libera attraverso pagine di segnalazioni di
risorse specifiche. È infatti quasi una norma di 'netiquette' che chi
rende disponibili informazioni su un determinato argomento, fornisca anche
una lista di link alle principali altre risorse esistenti in rete al
riguardo. Questo tipo di liste ragionate va naturalmente esso stesso
cercato e trovato, cosa che in genere viene fatta usando indici alfabetici
o cataloghi sistematici di risorse secondo le modalità sopra delineate.
Una volta però che abbiamo individuato una di queste pagine-miniera di
link specifici, potrà essere produttivo proseguire la nostra ricerca
attraverso di essa. Le risorse in tal modo segnalate presentano infatti
due importanti caratteristiche: sono state scelte in maniera esplicita e
ragionata, e la scelta è presumibilmente opera di una persona che conosce
bene il settore in questione. Abbiamo trovato comodo caratterizzare con
l'espressione navigazione orizzontale questa terza modalità di
ricerca su Web.
I motori di ricerca per
termini
Consideriamo innanzitutto un po' più da vicino i motori di ricerca
appartenenti alla prima delle categorie sopra considerate: la ricerca per
termini.
Come si è detto, in questi casi la ricerca avviene indicando una
parola, o una combinazione di parole, che consideriamo ragionevolmente
associata al tipo di informazione che vogliamo reperire. Questo
evidentemente può avvenire solo se abbiamo un'idea sufficientemente
chiara di quello che stiamo cercando, e se l'ambito della nostra ricerca
può essere associato in maniera abbastanza immediata ad un termine, o ad
un piccolo insieme di termini.
Il caso tipico è quello in cui la nostra ricerca riguarda una persona.
Scegliamo come esempio una ricerca di informazioni sulla scrittrice Jane
Austen, e vediamo come condurla utilizzando quelli che sono al momento
forse i due principali motori di ricerca per termini disponibili su
Internet: HotBot e AltaVista.
HotBot
HotBot (http://www.hotbot.com)
è nato nel 1996 per iniziativa di HotWired (http://www.hotwired.com),
la controparte in rete della rivista Wired e, come la sorella su
carta, sito 'di culto' per molti fra i nuovi profeti del digitale.
Nuovo ingresso nella ormai lunga lista dei motori di ricerca per
termini (al momento di scrivere Internet '96 HotBot non esisteva
ancora, ma ne segnalammo la nascita e le notevoli caratteristiche in uno
dei primi aggiornamenti in rete del manuale), HotBot si segnala sia per
numero di pagine indicizzate (quasi 60 milioni, si tratta al momento della
più vasta base dati di pagine Web indicizzata da un singolo motore di
ricerca) sia per la potenza delle opzioni messe a disposizione
dell'utente, attraverso una interfaccia coloratissima e divertente.
Le ricerche possono svolgersi sia su Web che su un archivio di
newsgroup Usenet, e le varie opzioni sono tutte disponibili attraverso
menu a tendina. Possiamo così decidere se svolgere una ricerca in AND
(opzione 'all the words'), in OR (opzione 'any of the words'), una ricerca
su nomi (opzione 'the person': viene cercata sia la stringa "Nome
Cognome" che quella "Cognome Nome"). Ricerche ancor più
avanzate possono essere effettuate attraverso l'opzione 'modify', che
permette di combinare fra loro ricerche con operatori differenti. Il
modulo di ricerca avanzata permette inoltre di selezionare il tipo di
documento (inclusi documenti non HTML come quelli scritti in Adobe
Acrobat, e addirittura immagini, mondi VRML, applet Java), la sua
provenienza geografica o 'ciberspaziale' (determinata attraverso il
dominio del server che lo ospita), le date estreme tra le quali effettuare
la ricerca. È anche possibile salvare come default la particolare
configurazione di ricerca che utilizziamo più frequentemente (ad esempio:
ricerca su nomi di persone, presentando 25 risultati alla volta, con
descrizioni brevi...). Insomma, come avrete capito, al momento HotBot ha
davvero pochi rivali; volendo trovare il pelo nell'uovo, va detto però
che il sito è talvolta più lento di quello Digital che ospita Altavista,
e che l'aggiornamento degli indici, all'inizio davvero rapido, sembra
procedere negli ultimi mesi con qualche ritardo (nonostante HotBot
dichiari una media di 10 milioni di pagine visitate al giorno, che
dovrebbe portarlo ad aggiornare tutto il proprio indice in meno di una
settimana).
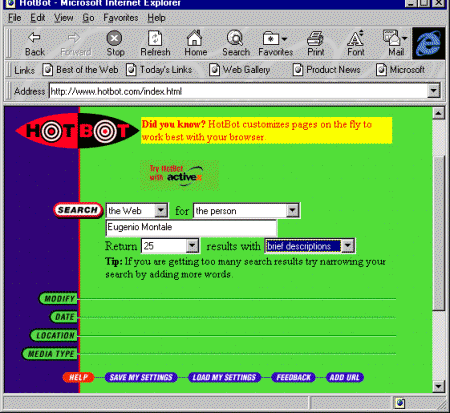
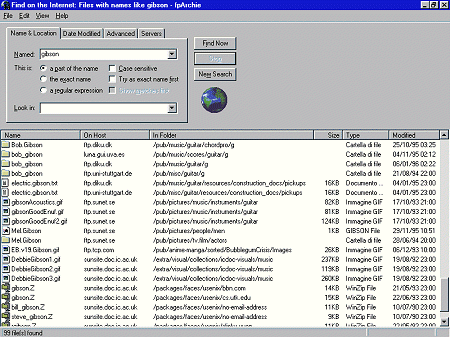
Figura 94
HotBot, il più ricco motore di ricerca per termini
A inizio marzo 1997, una ricerca con chiave 'Jane Austen' condotta su
HotBot portava a 10.451 pagine: fra le altre, pagine dedicate alla
scrittrice da università, da appassionati, da librai e case editrici;
versioni ipertestuali e testuali di molte fra le sue opere; programmi di
corsi universitari dedicati a Jane Austen; bibliografie; articoli
accademici che studiano i più disparati aspetti della sua letteratura, e
addirittura... barzellette ispirate a Jane Austen. Per avere un'idea della
mole del materiale disponibile, potete dare un'occhiata alla URL http://uts.cc.utexas.edu/~churchh/janeinfo.html.
Per confrontare i risultati con quelli relativi ad alcuni autori italiani,
nella stessa data una ricerca con chiave 'Eugenio Montale' portava a 481
pagine, e una ricerca con chiave 'Umberto Eco' a 4973 (questi dati
naturalmente sollecitano alcune riflessioni sui meccanismi della 'fama su
Web').
AltaVista
AltaVista è il risultato di un progetto di ricerca iniziato
nell'estate del 1995 nei laboratori di Palo Alto della Digital, una delle
principali aziende informatiche mondiali. L'indirizzo al quale
raggiungerlo è http://www.altavista.digital.com
(o anche solo http://altavista.digital.com).
A inizio marzo 1997, Altavista dichiara di indicizzare circa 31 milioni
di pagine; il dato numerico è inferiore a quello di HotBot, ma la cifra
è comunque impressionante — così come lo sono le statistiche fornite
per gli accessi, con 28 milioni di ricerche effettuate ogni giorno. Un
dato per la verità quasi eccessivo, dato che, nonostante le dispute sul
numero reale degli utenti di Internet, sembra difficile sostenere che il
numero di 'naviganti' in ogni singola giornata possa superare di molto
tale cifra. È chiaro comunque che, per molti internauti, il passaggio da
Altavista è una tappa quasi obbligata di ogni navigazione.
Le ricerche attraverso AltaVista sono possibili in due distinte
modalità: come 'simple query' e come 'advanced query'. La 'simple query'
mette a disposizione un modulo come quello qui sotto (in verità, un po'
deturpato dalla onnipresente pubblicità):

Figura 95
Il motore di ricerca AltaVista (simple query)
Occupandoci delle ricerche su newsgroup, abbiamo già considerato la
prima delle caselle: l'opzione standard è 'Search the Web', ma il menu a
tendina ci permette di scegliere anche l'opzione 'Search Usenet'. La
seconda casella permette di scegliere la forma in cui vogliamo ci siano
presentati i risultati della ricerca. 'Detailed form' produrrà una lista
di siti contenente i titoli delle pagine reperite, accompagnati dalle
prime due righe di testo, da una indicazione sulla dimensione in Kbyte
della pagina, e dalla data dell'ultima indicizzazione da parte del motore
di ricerca. 'Compact form' produrrà invece un elenco più scarno, in
forma tabellare. La 'standard form' preimpostata al momento di accedere al
sito è simile alla 'detailed form'.
Nella casella principale andranno inseriti il termine o i termini
cercati. Nel nostro esempio, li abbiamo racchiusi fra virgolette, per
indicare al motore di ricerca di considerarli come un termine unico:
troveremo solo le pagine in cui compare l'espressione 'Jane Austen', e non
quelle in cui compare solo il termine 'Jane', o solo il termine 'Austen',
o quelle in cui i due termini compaiono lontani. Se non avessimo usato le
virgolette, avremmo incluso nella ricerca anche questi casi — ma
AltaVista ci avrebbe comunque fornito per prime le pagine in cui i due
termini comparivano insieme, possibilmente nel titolo.
Il bottone 'Submit' (o il tasto 'Invio' della tastiera) serve ad
eseguire la ricerca impostata.
Il fatto di utilizzare la 'simple query' non deve ingannare: è
possibile compiere ricerche molto raffinate, usando fra gli altri gli
operatori '+' (va premesso ai termini che vogliamo necessariamente
presenti nella pagina), '-' (va premesso ai termini la cui occorrenza
vogliamo escludere), '*' (che funziona come 'wild card': il termine
'astronom*' corrisponderà sia ad 'astronomy' che ad 'astronomia', o
'astronomical'). È possibile anche limitare la ricerca a specifiche aree
dei documenti: ad esempio inserendo come termine da ricercare
'title:"Jane Austen"' avremmo trovato solo le pagine il cui
titolo contiene l'espressione 'Jane Austen'.
Per avere una descrizione dettagliata della sintassi ammissibile in una
'simple query' basterà fare click sull'icona 'Help' presente in apertura
della pagina.
Nel momento in cui scriviamo, una simple query con valore 'Jane Austen'
porta a un elenco di circa cinquemila pagine informative (oltre mille in
più del risultato che la stessa ricerca aveva dato nel marzo 1996, ma
circa la metà di quelle cui ci aveva condotto HotBot)
La 'Advanced query' mette a disposizione una finestra di dialogo più
complessa, e gli operatori booleani standard.
Nella casella 'Selection criteria' si può continuare a usare
"Jane Austen", ma gli operatori '+' e '-' non funzioneranno
più; possiamo invece raffinare la ricerca con operatori booleani (se
vogliamo eliminare tutte le pagine che parlano di Orgoglio e
Pregiudizio potremo scrivere ad esempio '"Jane Austen" NOT
Pride'). Per consentire la costruzione di espressioni di ricerca
complesse, è possibile anche utilizzare parentesi. Attraverso la casella
'Results Ranking Criteria' possiamo influenzare l'ordine in cui
visualizzare le pagine trovate (se 'Pride' lo scriviamo qui, le pagine che
trattano di Orgoglio e pregiudizio saranno visualizzate per prime);
possiamo anche eliminare le pagine 'poco aggiornate' (nel caso di una
ricerca su Jane Austen, questa possibilità non ha probabilmente un gran
senso), utilizzando le caselle nelle quali impostare la data iniziale e la
data finale di creazione per le pagine cercate.
Per avere un'idea un po' più precisa delle capacità di Altavista, e
riprendendo gli esempi fatti in precedenza, notiamo che una ricerca con
chiave 'Eugenio Montale' porta nel marzo 1997 a circa 200 pagine, e una
ricerca con chiave 'Umberto Eco' a circa 2000: anche in questi casi, circa
la metà di quelle raggiunte da HotBot.
Altri motori di ricerca
Progressivamente, diversi altri motori di ricerca basati su (tentativi
di) indicizzazione globale di World Wide Web si stanno avvicinando alla
copertura offerta da HotBot e Altavista, tanto che, se il primato generale
spetta al momento senz'altro a HotBot, la lotta per il secondo posto è
più aperta che mai. Va detto inoltre che strumenti diversi offrono
modalità di ricerca diverse, e non è detto che il motore più adatto per
una determinata ricerca sia necessariamente il più esteso in termini di
pagine indicizzate. Ricordiamo fra gli altri:
- Lycos (http://www.lycos.com)
il capostipite, nato come progetto sperimentale presso la Carnegie
Mellon University sotto la direzione di Michael Mauldin e
trasformatosi nel giugno 1995 in una vera e propria impresa, la Lycos
Inc. Fra gli aspetti interessanti di Lycos, l'indicizzazione separata
del 'Top 5% of the Web', che nelle intenzioni dovrebbe portare solo a
pagine di alto interesse grafico e contenutistico (ma ovviamente ogni
classificazione di questo tipo è assai opinabile).
- Infoseek (http://guide.infoseek.com/)
Come avevamo previsto in Internet '96, Infoseek ha
fortunatamente rinunciato alla scelta (anacronistica nel momento in
cui esistono motori di ricerca gratuiti con una base di dati
indicizzata più ricca) di far pagare le ricerche dopo la
visualizzazione dei primi 100 risultati, ed è quindi ormai anch'esso
gratuito (anche se — come per gli altri motori di ricerca — la
pubblicità ampiamente presente sulle sue pagine non lascia dubbi sul
carattere commerciale dell'iniziativa). Negli ultimi mesi Infoseek è
molto cresciuto, e ha integrato al motore di ricerca per termini un
catalogo sistematico piuttosto bene organizzato. Si proclama 'the
largest directory of the Web', ma non fornisce dati per suffragare
questa affermazione. I nostri test hanno dato sostanzialmente gli
stessi risultati ottenuti nel caso di Altavista: un po' più di 5.000
pagine su Jane Austen, 180 su Eugenio Montale, circa 2.200 su Umberto
Eco. Merita una citazione la capacità di Infoseek di individuare
anche argomenti correlati ('related topics') a quelli sui quali avete
svolto la ricerca. Così, ad esempio, una ricerca con chiave Isaac
Asimov fornirà come argomenti correlati 'fantascienza' e 'autori di
libri'; si tratta di una potenzialità interessante, ma sulla quale
per ora è bene non fare troppo affidamento: nel caso di Eugenio
Montale, ad esempio, come argomenti correlati abbiamo ottenuto la
corretta indicazione 'autori di libri', assieme a quella, più
discutibile (o rivelatrice?) di 'humor e divertimento'.
- Excite! (http://www.excite.com/)
Un altro motore di ricerca che ha conosciuto negli ultimi mesi un
notevole sviluppo, tanto che, secondo la società che lo gestisce,
Excite ha già superato Altavista per numero di pagine indicizzate.
Una pretesa che sembra confermata dalla nostra ricerca-test: oltre
6.500 pagine su Jane Austen, 274 su Montale, circa 2.600 su Umberto
Eco. La ricerca è assai semplice, e può avvenire fornendo le nostre
interrogazioni in linguaggio naturale (inglese, naturalmente). Buona
la sintassi della ricerca avanzata, con la possibilità di combinare
fra loro in maniera flessibile gli operatori booleani, usando anche le
parentesi. Il programma interpreta come nome proprio la combinazione
di due nomi con iniziali maiuscole, svolgendo in tal caso la corretta
ricerca di prossimità.
- Open Text (http://index.opentext.net).
Open Text accetta una sintassi di ricerca piuttosto evoluta; in questo
caso, tuttavia, la base delle pagine indicizzate è veramente
piuttosto limitata.
- WebCrawler (http://www.webcrawler.com),
un altro motore di ricerca 'storico', con una sintassi non proprio
intuitiva ma piuttosto potente, e una base di pagine indicizzate
lontana dagli standard di HotBot, Altavista, Excite e Infoseek. È
accompagnato da un catalogo sistematico di risorse. Funziona di
default in OR, ed accetta operatori booleani e di prossimità.
- World Wide Web Worm (http://wwww.cs.colorado.edu/home/mcbryan/WWWW.html),
anche lui fra i precursori, anche lui ormai decisamente superato.
L'home page riporta il riconoscimento di 'miglior strumento di ricerca
del 1994', una data che per il Web è ormai quasi archeologia.
Col moltiplicarsi dei motori di ricerca, acquistano importanza altri
due tipi di risorse che può essere utile ricordare in conclusione: i
cosiddetti strumenti di 'metaricerca', e gli indici di indici.
Le 'metaricerche' consistono, in sostanza, nell'inviare in maniera
sequenziale o contemporaneamente a più motori di ricerca il termine o i
termini che ci interessano. L'invio sequenziale è analogo alla
consultazione successiva di più motori di ricerca: è comodo poterlo fare
da un'unica pagina, ma non vi è alcun 'valore aggiunto' fornito da uno
strumento di questo tipo. Provate comunque, fra i servizi che rientrano in
questa categoria, EZ-Find (http://www.theriver.com/TheRiver/Explore/ezfind.html),
Find-It (http://www.cam.org/~psarena/find-it.html),
Starting Point (http://www.stpt.com/),
IntelliScope (http://wizard.inso.com).
Decisamente più appetibile è invece la possibilità di consultare contemporaneamente
più motori di ricerca, in modo da ottenere un'unica lista di
risposte. Ai due servizi di questo tipo che avevamo segnalato in Internet
'96 se ne sono nel frattempo aggiunti diversi altri. Savvy Search (http://guaraldi.cs.colostate.edu:2000/form)
e Meta Crawler (http://www.metacrawler.com)
restano comunque fra i più completi. Savvy Search — che dispone anche
di una interfaccia in italiano — permette di scegliere se integrare o no
i risultati eliminando le ripetizioni, ma a prezzo di un sostanziale
ritardo nella visualizzazione dei risultati; inoltre è spesso
sovraffollato (nel qual caso rifiuta di svolgere la ricerca richiesta), e
la lista di risultati ottenuta non sembra seguire alcun ordine di
rilevanza. Meta Crawler è moderatamente più efficiente: anch'esso
richiede una certa attesa per la visualizzazione dei risultati, ma la
lista che si ottiene è priva di duplicati e informativa. Anche in questo
caso, tuttavia, l'ordine di visualizzazione non è sempre quello che ci si
aspetterebbe.
|