| |
Questioni di stile
World Wide Web è stato concepito come un sistema per la distribuzione
di semplici documenti tecnici su rete geografica. La comunità di utenti a
cui era inizialmente destinata era molto ristretta, fortemente legata al
mondo della ricerca scientifica, non necessariamente in possesso di
particolari competenze informatiche, e scarsamente preoccupata degli
aspetti qualitativi nella presentazione dell'informazione. Per questa
ragione nello sviluppo delle tecnologie di base sono state perseguite la
semplicità di uso e di implementazione.
Queste caratteristiche hanno notevolmente contribuito al successo di
Web. Ma con il successo lo spettro dei fornitori di informazione si è
allargato: World Wide Web e diventata un vero e proprio sistema di editoria
elettronica online. Ovviamente l'espansione ha suscitato esigenze ed
aspettative che non erano previste nel progetto originale, stimolando una
serie di revisioni e di innovazioni degli standard tecnologici originari.
L'aspetto che ha suscitato maggiore interesse è l'accrescimento della
capacità di gestione e controllo dei documenti multimediali e dei testi
elettronici su Web, e il potenziamento del linguaggio utilizzato per la
loro creazione.
Come sappiamo, allo stato attuale il formato usato nella realizzazione
di pagine Web è il linguaggio HTML, di cui esistono diverse versioni:
- uno standard ufficiale definitivo, HTML 2, ormai invecchiato, e
assolutamente limitato
- un nuovo standard, HTML 3.2, rilasciato dal W3C ma non dalla IETF,
scaturito dal lunghissimo lavoro di definizione della versione 3, che
non ha mai visto ufficialmente la luce
- una serie di 'dialetti' con estensioni proposte delle varie case
produttrici di browser.
Gran parte delle estensioni proprietarie hanno lo scopo di ottenere
effetti grafici ed editoriali spettacolari. L'obiettivo che spinge aziende
come Netscape e Microsoft ad introdurre innovazioni è la conquista di una
posizione di monopolio nel mercato, dato che le nuove caratteristiche
sono, almeno in prima istanza, riconosciute e interpretate correttamente
solo dai rispettivi browser. A tutto ciò si aggiunge la recente
introduzione dei plug-in e dei controlli ActiveX, che permettono di
distribuire documenti in formati proprietari, contribuendo all'incremento
della confusione.
Questa corsa all'ultima innovazione, dunque, se molto spesso migliora
l'aspetto e la fruibilità delle pagine pubblicate su Web, ha degli
effetti devastanti sul piano della portabilità dei documenti. Per il
momento i dialetti HTML interpretati dai browser più diffusi coincidono
quasi del tutto, ma questo non è stato vero in passato, e non è detto
che resti vero in futuro. Insomma, il rischio di vedere nascere dei
confini nell'universo aperto della rete è incombente: qualcuno ha
addirittura parlato di una vera e propria balcanizzazione di World Wide
Web. La scelta di introdurre nuovi comandi per ogni effetto grafico che si
vuole ottenere, peraltro, introduce inconsistenze formali nella
definizione del linguaggio HTML, e riduce la sua utilità in applicazioni
complesse come ad esempio l'aggiornamento di database tramite Web, o i
sistemi di information retrieval.
Per agevolare uno sviluppo 'ecologico' di World Wide Web, ed evitare
che le tensioni indotte dal mercato limitino la universalità di accesso
all'informazione che aveva caratterizzato il progetto iniziale, il W3
Consortium promuove, come si è già accennato, una importante attività
di innovazione e di standardizzazione. Nel settore specifico che stiamo
trattando in questo paragrafo, sono emerse due importanti proposte che
potrebbero cambiare il volto della rete.
La prima prospetta la generalizzazione del supporto allo Standard
Generalized Markup Language (SGML) su World Wide Web. L'idea è molto
semplice: HTML è una particolare applicazione SGML, che risponde ad
alcune esigenze ma non a tutte; perché non modificare i protocolli Web
per consentire di usare anche altre applicazioni SGML, potenziando le
capacità di interpretazione degli attuali browser? Questo garantirebbe ai
fornitori di contenuti un notevole potere di controllo sulla qualità e
sulla struttura delle informazioni pubblicate, oltre ai molteplici
vantaggi impliciti nella tecnologia SGML. La seconda innovazione, peraltro
strettamente collegata alla prima, riguarda l'introduzione dei fogli di
stile per gestire la presentazione grafica delle pagine Web.
SGML e l'editoria
elettronica in rete
Lo Standard Generalized Markup Language, ideato e sviluppato da Charles
Goldfarb, è un sistema per la creazione e l'interscambio di documenti
elettronici adottato dalla International Standardization Organization (ISO).
Il rilascio ufficiale dello standard risale al 1986, ma solo ora questa
potente tecnologia comincia a guadagnare consensi, e ad essere utilizzata
in un vasto spettro di applicazioni concrete.
L'idea alla base di SGML è quella dei linguaggi di markup, che abbiamo
già visto nel paragrafo introduttivo su HTML. Si possono distinguere due
tipologie di linguaggi di markup:
- markup procedurale
- markup analitico
Il primo tipo (i cui testimoni più illustri sono lo Script, il TROFF,
il TEX) consiste di istruzioni operative che indicano la struttura
tipografica della pagina (il lay-out), le spaziature,
l'interlineatura, i caratteri usati. Questo tipo di marcatura è detta procedurale
in quanto indica ad un programma le procedure di trattamento cui deve
sottoporre la sequenza di caratteri al momento della stampa. Il markup
dichiarativo invece permette di descrivere la struttura astratta di un
testo. SGML rientra in questa seconda classe.
Per la precisione, più che un linguaggio, lo SGML è un metalinguaggio.
Esso prescrive precise regole sintattiche per definire un insieme di
marcatori e di relazioni tra marcatori in una tabella, denominata Document
Type Definition (DTD), ma non dice nulla per quanto riguarda la
tipologia, la quantità e il nome dei marcatori. Questa astrazione, che
permette di definire infiniti linguaggi di marcatura, costituisce il
nucleo e la potenza dello SGML: in sostanza, SGML serve non già a marcare
direttamente documenti, ma a costruire, rispettando standard comuni e
rigorosi, specifici linguaggi di marcatura adatti per le varie esigenze
particolari.
Un linguaggio di marcatura SGML a sua volta descrive la struttura
logica di un documento, e non prescrive la sua forma fisica (questo, come
vedremo, è il compito di un foglio di stile). La struttura astratta di un
documento viene specificata dichiarando gli elementi che lo costituiscono,
come titolo, paragrafo, nota, citazione, etc.,
e le relazioni che tra questi intercorrono. A ciascun elemento corrisponde
un marcatore. Una volta definito un determinato linguaggio, è possibile
utilizzare i marcatori per codificare il contenuto di documenti
elettronici.
Un linguaggio di marcatura che rispetti le specifiche SGML - e gli
eventuali sistemi informativi ad esso collegati - viene definita una SGML
application. Sicuramente la più diffusa in assoluto di queste
applicazioni è proprio HTML, sebbene il legame con SGML sia sconosciuto
alla maggioranza dei suoi stessi utilizzatori. Ma esistono molte altre
applicazioni SGML, alcune delle quali sono molto complesse e potenti.
Pensate che alcune di queste applicazioni (come la Text Encoding
Initiative, una DTD sviluppata dalla comunità internazionale degli
studiosi di informatica umanistica) mettono a disposizione centinaia di
istruzioni di codifica.
La codifica SGML dei testi elettronici, oltre alla sua potenza
espressiva, offre una serie di vantaggi dal punto di vista del trattamento
informatico. In primo luogo, poiché un file SGML può essere composto di
soli caratteri ASCII stampabili, esso è facilmente portabile su ogni tipo
di computer e di sistema operativo. Inoltre un testo codificato in formato
SGML può essere utilizzato per scopi differenti (stampa su carta,
presentazione multimediale, analisi tramite software specifici,
elaborazione con database, creazione di corpus linguistici automatici),
anche in tempi diversi, senza dovere pagare i costi di dolorose
conversioni tra formati spesso incompatibili. Ed ancora, la natura
altamente strutturata di un documento SGML si presta allo sviluppo di
applicazioni complesse. Possiamo citare ad esempio l'aggiornamento di
database; la creazione di strumenti di information retrieval contestuali;
la produzione e la manutenzione di pubblicazioni articolate come
documentazione tecnica, manualistica, corsi interattivi per l'insegnamento
a distanza.
La possibilità di distribuire di documenti elettronici in formato SGML
su World Wide Web fornirebbe dunque un evidente valore aggiunto alla
editoria elettronica online. Ogni editore potrebbe utilizzare l'insieme di
codifiche che maggiormente risponde alle sue esigenze, o eventualmente
produrne di nuovi, senza attendere il rilascio di aggiornamenti ufficiali.
Ad ogni applicazione SGML sarebbero associati uno o più fogli di stile
che garantirebbero un esatto controllo della presentazione su video dei
documenti pubblicati.
La piena attuazione di questa evoluzione, tuttavia, si scontra con
diversi ostacoli:
- l'uso generico di SGML richiede una vera e propria ristrutturazione
della attuale architettura di World Wide Web
- l'implementazione di un browser SGML generico è dal punto di vista
computazionale decisamente più complessa di quella di un normale
browser HTML, e peraltro comporta degli obblighi tecnici che limitano
l'efficienza del trasferimento di informazioni sulla rete
- l'uso consolidato di HTML ha generato consuetudini ed attese
difficilmente modificabili.
Per superare questi problemi sono state proposte diverse soluzioni. Una
soluzione intermedia per la pubblicazione di documenti SGML su Internet
consiste nella utilizzazione di un browser SGML che funzioni come
visualizzatore esterno o come plug-in di un normale Web browser. Uno
strumento di questo tipo già esiste: si chiama Panorama, ed è
stato sviluppato dalla SoftQuad.
La seconda soluzione consiste nella definizione di un sottoinsieme
semplificato di SGML pensato appositamente per la creazione di documenti
su Web. Il W3C ha recentemente avviato lo sviluppo di un linguaggio di
questo tipo, denominato Extensible Markup Language (XML), le cui
caratteristiche tecniche facilitano notevolmente l'implementazione di un
browser, pur mantenendo la piena compatibilità, e i vantaggi, offerti
dallo standard ISO.
SoftQuad Panorama
Panorama è un browser SGML generico, prodotto dalla SoftQuad, una
delle aziende leader nel mercato di settore. Il programma è disponibile
in due versioni: una versione freeware, con funzionalità limitate, e una
versione commerciale, di cui è stata recentemente rilasciata la nuova
release 2. Entrambe possono essere usate sia come programmi autonomi, per
visualizzare documenti locali, sia come applicazioni di supporto per un
browser Web. In questo modo il documento SGML può contenere al suo
interno dei link ad altri documenti remoti, esattamente come un normale
file HTML. Panorama 2 viene distribuito anche come controllo ActiveX per
Explorer e come plug-in per Netscape (ancora in beta test nel momento in
cui scriviamo).
Panorama fa parte di una serie di applicazioni che la SoftQuad ha
realizzato per l'uso di SGML su Web, e supporta anche l'annunciato XML.
Informazioni a riguardo possono essere ovviamente trovate sul sito Web
della società, all'indirizzo http://www.softquad.com.
Per permettere al browser Web di avviare Panorama quando riceve un file
SGML da Internet, occorre configurarlo appositamente. Le informazioni
relative al mime type da inserire nella finestra di configurazione delle
'Helper applications' sono le seguenti:
- mime type: sgml
- Mime Sub Type: x-sgml
- file extension: sgm, sgml
- applicazione da avviare: x:\path\panorama.exe
L'interfaccia utente di Panorama si differenzia da quella di un
consueto browser Web. La finestra principale è divisa in due aree. La
parte sinistra può contenere un indice dei contenuti, o una
rappresentazione ad albero della struttura del documento, la parte destra
mostra il documento. Per passare da una visualizzazione all'altra si usano
i comandi 'Contents' e 'SGML Tree' nel menu 'Navigator'.
L'indice, detto navigatore, viene generato automaticamente dal
programma usando i marcatori che identificano i titoli di vario livello
presenti nel documento. Le voci dell'indice sono attive e permettono di
saltare direttamente al capitolo o paragrafo selezionato. L'albero invece
mostra i rapporti tra i vari elementi che costituiscono il documento.
Anche in questo caso se si seleziona con il mouse un certo elemento, viene
evidenziato il contenuto corrispondente nella finestra del testo.
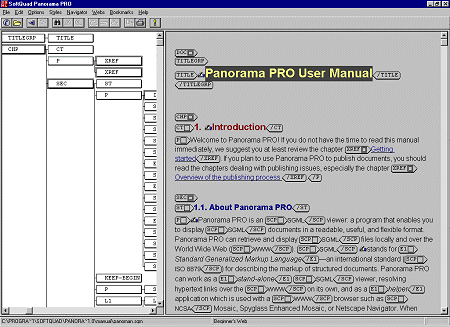
Figura 88
Il browser SGML Panorama 2 della SoftQuad. I marcatori SGML sono
visibili
Il testo, a sua volta, può essere visualizzato in due modalità:
- solo testo formattato
- testo formattato con i marcatori SGML
Per passare da una modalità all'altra occorre selezionare o
deselezionare il comando 'Show Tags' del menu 'Options'. La figura
precedente mostra l'aspetto di un file SGML con i marcatori visibili. È
possibile così vedere immediatamente che tipologia di codifica ha avuto
ogni segmento del testo, ed usufruire delle informazioni strutturali
veicolate dalla codifica. La Figura 89 invece mostra la stessa porzione di
file con il solo contenuto. Le parti di testo sottolineate, codificate con
il tag <XREF>, sono dei link attivi. In questo caso abbiamo usato
Panorama 2, in versione controllo ActiveX. Come potete vedere in questo
caso la finestra è interna a quella di Explorer, la cui barra dei menu
mostra anche i comandi dell'applicazione ospite.
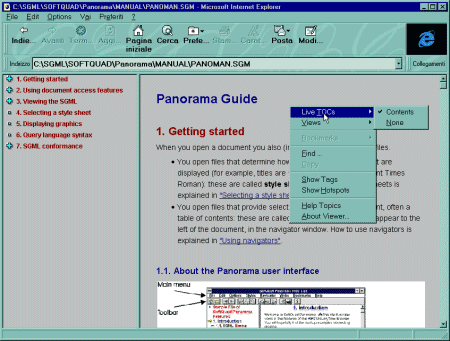
Figura 89
Panorama 2 in versione Active X, con la finestra del navigatore attiva
L'impaginazione e la formattazione dei caratteri avviene attraverso
l'associazione di un foglio di stile al file del documento. Il meccanismo
dei fogli di stile di Panorama usa una sintassi è in formato
proprietario, ma le versione due ha anche il supporto per lo standard
CSS1. Ogni tipo di documento (DTD in terminologia SGML) può avere più
fogli di stile associati. Se Panorama riceve un file per il quale ha uno o
più fogli di stile, allora lo applica, altrimenti ne richiede uno al
server remoto.
Grazie alla codifica SGML, Panorama è dotato di strumenti di ricerca
interna al file notevolmente più avanzati rispetto ai normali browser
HTML. È possibile cercare le occorrenze di un dato elemento, oppure le
occorrenze di una certa stringa di testo contenute solo all'interno di
determinati elementi. La sintassi per effettuare le ricerche prevede l'uso
di operatori logici (AND, OR) e di operatori di relazione (IN, CONT). Ad
esempio, se vogliamo cercare tutte le occorrenze di "style" solo
nei paragrafi del corpo del testo, occorre prima attivare la finestra di
dialogo con il comando 'Search' nel menu 'Edit', e poi digitare quanto
segue:
style in <P>
Come appare evidente, le potenzialità di questo programma sono
veramente notevoli. Non possiamo in questa sede approfondire l'analisi di
tutte le funzionalità, che del resto sono disponibili solo nella versione
commerciale, anche perché sarebbe necessaria una conoscenza più
approfondita delle caratteristiche dello SGML. Ma crediamo che questa
veloce ricognizione di un prodotto peraltro assai 'giovane' permetta di
affermare che la diffusione di tecnologie ed applicazioni SGML può
costituire un vero e proprio punto di svolta per l'evoluzione della
editoria elettronica e in particolare della editoria in rete.
XML
Extensible Markup Language (XML) è il più recente ed interessante
progetto promosso dal W3 Consortium. Obiettivo dell'iniziativa è
l'introduzione di un meccanismo per estendere e personalizzare la
struttura dei documenti utilizzabili su Web, superando così i limiti
imposti da un insieme chiuso di marcatori, come avviene per HTML.
Il progetto XML, che rientra nella SGML Activity dell'organizzazione,
è iniziato alla fine del 1996. L'attività di definizione del nuovo
standard è condotta da un apposito gruppo di lavoro (SGML Working
Group), composto da oltre ottanta esperti mondiali delle tecnologie
SGML, e da una commissione (SGML Editorial Review Board) deputata
alla redazione delle specifiche. I materiali pubblicati, insieme ad
informazioni ed aggiornamenti sono pubblicati periodicamente su Web
all'indirizzo http://www.w3.org/pub/WWW/MarkUp/SGML/Activity.
Il progetto XML si articola in tre fasi: la prima fase consiste nella
elaborazione delle specifiche del linguaggio in sé. Una prima bozza,
pressoché definitiva, è stata rilasciata nel novembre del 1996, mentre
il rilascio ultimo è fissato per la metà del 1997. La seconda fase
prevede la definizione di una serie di meccanismi standard per la
costruzione di collegamenti ipertestuali. La terza fase infine riguarda la
definizione di uno o più linguaggi per fogli di stile che potranno essere
associati ad un documento XML.
XML, come accennato sopra, è un sottoinsieme di SGML semplificato ed
ottimizzato specificamente per applicazioni in ambiente World Wide Web.
Dunque si tratta di un vero metalinguaggio, che permette di specificare
molteplici classi di linguaggi di marcatura, e non una semplice
applicazione SGML.
Rispetto all'illustre e potente predecessore, richiede una curva di
apprendimento di gran lunga minore (le specifiche constano di venticinque
pagine contro le cinquecento dello standard ISO), e soprattutto è
notevolmente più facile da implementare. Infatti alcune delle
caratteristiche più esoteriche di SGML, che ne accrescono la complessità
computazionale, sono state eliminate. La semplificazione tuttavia non
comporta incompatibilità: un documento XML valido è sempre un documento
SGML valido (naturalmente non vale l'inverso). La trasformazione di una
applicazione o di un documento SGML in uno XML è, nella maggior parte dei
casi, una procedura automatica.
I lavori relativi alle fase due del progetto XML, nel momento in cui
stiamo scrivendo sono ancora in una fase preliminare. Sicuramente anche in
questo settore le innovazioni saranno molte. Allo stato attuale su Web
esiste un solo tipo di collegamento ipertestuale, unidirezionale e privo
di qualsiasi informazione circa la destinazione e la tipologia del link.
XML invece sarà dotato di un sistema articolato di costrutti per
specificare collegamenti, ereditato da altre applicazioni SGML come HyTime
e TEI, e in grado di supportare destinazioni multiple (link uno a molti),
e tipologie esplicite.
Infine, la fase tre sarà dedicata alla individuazione di un sistema si
fogli di stile per specificare le caratteristiche fisiche e grafiche di un
documento XML. Al momento non esistono ancora chiare indicazioni su quale
sarà il linguaggio scelto per questo scopo. Con ogni probabilità la
scelta cadrà sul linguaggio DSSSL, anche se non si esclude l'indicazione
di più di un meccanismo standard, tra cui gli utenti potranno scegliere
quello più adeguato alle loro esigenze. Per maggiori informazioni su
fogli di stile rimandiamo al prossimo paragrafo
Insomma il progetto XML nel suo complesso provvede una collezione di
specifiche standard che permettono di creare, gestire e mantenere
applicazioni ipermediali complesse su World Wide Web giovandosi delle
potenzialità dei sistemi di markup generici. La sua applicazione, potrà
rappresentare uno vero e proprio salto evolutivo, affiancandosi per
rilevanza all'introduzione del linguaggio Java.
Naturalmente affinché questo accada è necessario che l'industria
delle tecnologie Internet, ed in particolare le due aziende leader del
settore, lo accolga e lo supporti. Da questo punto di vista la situazione
è ancora interlocutoria. La Microsoft sta partecipando, con un suo
esponente, Jean Pauli, alla definizione di XML; anche se non ha fatto al
riguardo alcun annuncio ufficiale, sembra avere una posizione favorevole,
in linea di principio, ad implementare nelle versioni future del suo
browser funzionalità basate su standard aperti.
Diversamente Netscape non ha dimostrato finora alcun interesse verso il
lavoro in corso al W3C. La politica commerciale della attuale leader nel
mercato Internet sembra improntata ad un certo distacco verso l'attività
di standardizzazione, probabilmente nel tentativo di mantenere la
posizione dominante, o meglio di difenderla dall'attacco di un gigante
come Microsoft. Ma come la storia di Internet fino ad oggi ha dimostrato,
qualsiasi tentativo di limitare la natura aperta delle tecnologie di rete
viene inesorabilmente condannato al fallimento. È auspicabile che
Netscape, ritornando allo spirito di frontiera che l'ha caratterizzata in
passato, sappia cogliere la novità rappresentata da XML, e aiutare in
questo modo lo sviluppo della rete.
I fogli di stile
Se le tecnologie SGML/XML di cui abbiamo parlato nei paragrafi
precedenti riguardano il potenziamento del lato strutturale, per così
dire, dei documenti pubblicati su World Wide Web, l'idea di utilizzare i
fogli di stile è stata avanzata per migliorarne l'aspetto formale.
Nella attuale architettura di World Wide Web le regole di formattazione
ed il rendering grafico di un documento sono codificati nel
browser. Il controllo sull'aspetto della pagina da parte dell'autore è
molto limitato, e peraltro si basa su un insieme di marcatori HTML che
possono introdurre inconsistenze strutturali nel documento. L'introduzione
dei fogli di stile risolve entrambi i problemi poiché:
- consente una cura dettagliata del progetto grafico di una pagina Web
- separa la specificazione della grafica della struttura logica del
contenuto.
Questo apre la strada allo sviluppo di un vero design grafico per le
pubblicazioni in rete, esigenza molto sentita nella editoria
professionale.
Il concetto di foglio di stile nasce nell'ambito delle tecnologie di word
processing e desktop publishing. L'idea alla base di questa
tecnica è quella di separare il contenuto testuale di un documento
elettronico dalle istruzioni che ne governano l'impaginazione, le
caratteristiche grafiche e la formattazione. Per fare questo è necessario
suddividere il testo in blocchi etichettati ed associare poi ad ogni
blocco uno specifico stile, che determina il modo in cui quella
particolare porzione del testo viene impaginato sul video o stampato su
carta. Ad esempio, ad un titolo di capitolo può essere associato uno
stile diverso da quello assegnato a un titolo di paragrafo o al corpo del
testo (lo stile 'titolo di capitolo' potrebbe prevedere, poniamo, un
carattere di maggiori dimensioni e in grassetto, la centratura, un salto
di tre righe prima dell'inizio del blocco di testo successivo; a un blocco
di testo citato potrebbe invece essere assegnato uno stile che prevede un
corpo lievemente minore rispetto al testo normale, e dei margini maggiori
a sinistra e a destra per poterlo 'centrare' nella pagina). Per chi usa un
moderno programma di scrittura come Microsoft Word o Wordperfect questo
processo, almeno ad un livello superficiale, dovrebbe risultare alquanto
familiare.
|